100만 명의 동시 접속자를 견디는 AI 쇼핑카트: DB 트랜잭션의 늪에서 벗어나는 법
상태 유지(Stateful) AI 에이전트의 확장성 병목을 해결하고, 고비용 트랜잭션을 대체하는 아키텍처 패턴을 탐구합니다.
최근 AI 에이전트 서비스를 설계하다 보면 꽤 흥미로운 현상을 발견하게 됩니다. 사용자의 맥락을 기억하는 ‘상태 유지(Stateful)’ 에이전트가 사용자 경험은 훨씬 좋지만, 정작 시스템 지표를 보면 응답 시간이 상태가 없는(Stateless) 에이전트보다 최대 3.3배나 더 느리더라고요. 보통 스테이트리스가 50~150ms 정도라면, 스테이트풀은 150~500ms까지 튀곤 합니다 [1]. 평소에는 티가 안 나겠지만, 동시 접속자가 수십만 명으로 늘어나는 순간 이 작은 차이가 시스템 전체를 무너뜨리는 치명적인 지연으로 이어집니다.
결국 초대규모 환경의 AI 에이전트는 우리가 흔히 쓰던 표준 DB 트랜잭션 기반의 상태 관리로는 비용과 성능의 한계에 부딪힐 수밖에 없어요. 이제는 상태를 서버 밖으로 밀어내고, 비동기적인 패턴으로 전환하는 설계가 선택이 아닌 필수인 시대가 된 거죠.
AI 에이전트의 ‘상태(State)’가 만드는 달콤한 경험과 가혹한 비용
우선 ‘상태(State)’라는 게 왜 필요한지부터 짚어볼까요? AI 쇼핑카트를 예로 들어보죠. 사용자가 “아까 봤던 빨간색 운동화에 어울리는 양말 추천해줘”라고 했을 때, 에이전트가 “아까 어떤 운동화를 보셨나요?”라고 되묻는다면 최악의 경험이겠죠. 상태 유지 에이전트는 사용자의 히스토리와 맥락을 기억해서 이런 반복적인 입력을 없애줍니다.
재미있는 건, 개별 응답 속도는 느려지지만 전체적인 작업 완료 시간(Task Completion Time)은 오히려 줄어든다는 점이에요.
“Stateful agents often complete tasks faster overall because they don’t require users to repeat information.” [1]
(상태 유지 에이전트는 사용자가 정보를 반복할 필요가 없게 하여 전체 작업 속도를 높입니다.)
하지만 엔지니어 입장에서 이 ‘달콤함’의 대가는 가혹합니다. 매 요청마다 이전 컨텍스트를 조회하고 처리해야 하니 개별 응답 속도가 떨어지는 건 당연하고, 서버가 기억해야 할 정보가 많아지면서 메모리 풋프린트가 크게 증가합니다. 트랜잭션 이력이나 구성 베이스라인 같은 데이터를 계속 들고 있어야 하니, 서버 한 대가 감당할 수 있는 가용 자원이 빠르게 줄어들게 되죠 [2].
100만 명의 동시 접속자: 왜 표준 DB 트랜잭션은 무너지는가
자, 이제 접속자가 100만 명으로 늘어났다고 가정해 봅시다. 이때 가장 먼저 무너지는 게 바로 전통적인 상태 관리 방식이에요.
가장 단순하게 서버 메모리에 세션을 저장하는 방식을 쓴다고 쳐보죠. 그러면 사용자는 반드시 처음 접속했던 그 서버로만 가야 하는 ‘스티키 세션(Sticky Session)’ 설정이 필요합니다. 로드 밸런싱이 굉장히 복잡해지고, 만약 서버 한 대가 죽으면 그 서버에 있던 수천 명의 쇼핑카트 정보가 순식간에 날아갑니다 [3].
그렇다고 모든 상태를 중앙 DB의 트랜잭션으로 처리하면 어떨까요? 더 심각한 병목이 기다리고 있습니다. 수많은 에이전트가 동시에 같은 사용자 상태를 업데이트하려고 하면 DB 락(Locking) 경쟁이 벌어집니다. 네트워크 라운드트립은 늘어나고 DB I/O 비용은 기하급수적으로 치솟죠. 결국 서버를 아무리 옆으로 늘려도(Horizontal Scaling), 상태를 동기화하는 데 드는 오버헤드가 서버 증설로 얻는 이득을 다 깎아먹는 상황이 발생합니다 [4].
확장 가능한 AI 쇼핑카트를 위한 아키텍처 패턴
그럼 어떻게 해야 할까요? 핵심은 ‘상태의 외부화’와 ‘비동기화’입니다.
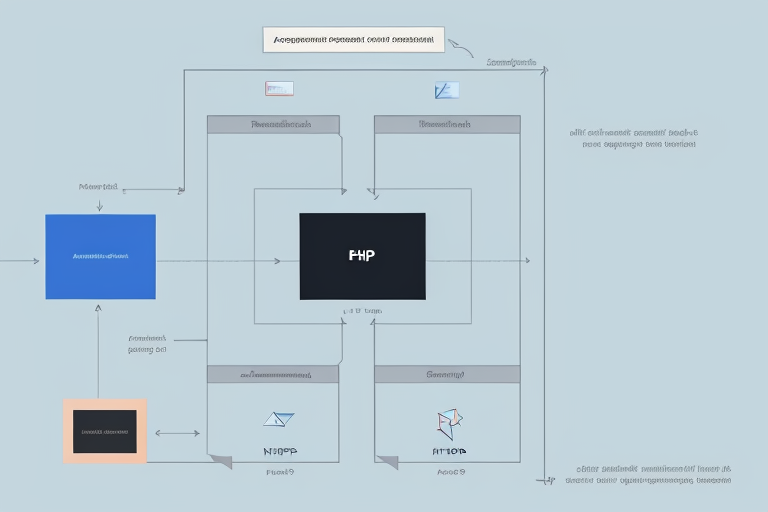
먼저 세션 데이터를 서버 메모리가 아닌 Redis 같은 고속 외부 저장소로 완전히 분리하세요. 이렇게 하면 어떤 서버가 요청을 받아도 외부 저장소에서 상태를 읽어와 처리할 수 있어 확장성이 비약적으로 좋아집니다 [3]. 여기에 토큰 기반 인증을 더해, 서버가 메모리에 세션을 저장하지 않고도 사용자 신원을 확인할 수 있게 설계하는 것이 정석입니다 [5].
더 나아가, 쓰기 작업이 많은 쇼핑카트 특성상 단순 CRUD 트랜잭션보다는 CQRS(명령 및 조회 책임 분리)와 이벤트 기반 아키텍처(EDA)를 도입하는 걸 추천합니다. 모든 상태 변경을 ‘이벤트’로 기록하고 비동기적으로 처리하면, 쓰기 성능을 극대화하면서도 나중에 문제가 생겼을 때 추적하기가 훨씬 쉽거든요 [4].
실제로 이런 구조를 구현한다면 아래와 같은 설정 방향이 될 겁니다.
# Redis를 활용한 상태 외부화 및 캐싱 설정 예시
state_management:
provider: redis
connection:
host: "redis-cluster.internal" # 고가용성을 위한 클러스터 구성
port: 6379
timeout: 200ms # AI 응답 지연을 최소화하기 위한 짧은 타임아웃
cache_policy:
ttl: 3600s # 세션 유지 시간 1시간
strategy: "write-through" # DB와 캐시의 일관성을 위한 쓰기 전략
# 이벤트 기반 상태 업데이트 설정
event_bus:
type: "kafka"
topics:
- "cart-updated-event" # 쇼핑카트 변경 사항을 비동기로 전파
- "user-context-changed"
partition_strategy: "user_id" # 동일 사용자의 이벤트 순서 보장을 위해 user_id로 파티셔닝이 설정의 핵심은 서버를 완전히 ‘멍청하게(Stateless)’ 만드는 것입니다. 서버는 요청이 오면 Redis에서 상태를 읽고, 변경 사항은 Kafka로 던진 뒤 바로 응답하는 구조죠. 이렇게 하면 서버 대수를 10대에서 1,000대로 늘려도 성능이 선형적으로 증가합니다.
짚고 넘어갈 한계와 안티패턴
물론 스테이트리스(Stateless)가 만능 열쇠는 아닙니다. 무턱대고 도입했다가 오히려 더 큰 늪에 빠지는 경우가 많아요.
가장 흔한 실수가 모든 상태를 요청(Request)에 담아 보내는 겁니다. 클라이언트가 상태를 다 가지고 있게 하면 서버는 편하겠지만, 요청 크기가 비대해지면서 네트워크 대역폭 소모가 심해집니다 [4]. 결국 전송량 증가가 성능 저하로 이어지는 역설적인 상황이 오죠.
또한, 상태를 외부 저장소로 옮겼더니 이제는 그 저장소가 단일 장애점(SPOF)이 되거나 병목 지점이 되는 경우도 허다합니다. 매 요청마다 외부 저장소를 조회하는 ‘Chatty’한 통신 패턴이 반복되면, 네트워크 지연 때문에 다시 응답 속도가 느려집니다 [5]. 특히 분산 환경에서 여러 에이전트가 동시에 동일한 자원에 접근할 때 발생하는 데이터 일관성 문제는 설계 단계에서 매우 정교하게 다뤄야 합니다 [2].
핵심 요약
- 트레이드오프: 상태 유지 AI 에이전트는 UX를 높여주지만, 개별 응답 속도를 늦춘다.
- 메모리 관리: 100만 명 규모의 서비스에서 서버 메모리 기반 세션 관리는 반드시 실패한다.
- 외부화 전략: 상태를 Redis 같은 외부 저장소로 분리하고, 토큰 기반 설계를 통해 서버를 스테이트리스하게 만들어야 한다.
- 비동기 처리: 단순 DB 트랜잭션보다는 이벤트 소싱과 CQRS를 도입해 쓰기 성능과 추적 가능성을 동시에 잡아야 한다.
- 하이브리드 접근: 무조건적인 스테이트리스보다는 워크로드에 따라 상태를 클라이언트, 캐시, DB에 적절히 분산 배치하는 전략이 필요하다.
사실 저도 예전에는 “그냥 DB 사양 높이고 캐시 좀 붙이면 되겠지”라고 생각했던 적이 있습니다. 하지만 규모의 경제가 작동하는 임계점을 넘어서면, 단순한 튜닝으로는 해결 안 되는 ‘구조적 한계’가 반드시 옵니다. 중요한 건 최신 기술을 쓰는 게 아니라, 우리 서비스의 상태가 얼마나 무거운지, 그리고 그 상태를 유지하기 위해 지불하는 비용이 사용자 경험의 가치보다 큰지를 끊임없이 질문하는 것이더라고요.
참고 자료 (References)
1. [ruh.ai] Stateful vs Stateless AI Agents: Architecture Guide — https://www.ruh.ai/blogs/stateful-vs-stateless-ai-agents 2. [algomox.com] Stateful vs Stateless Agents in IT Ops: Design Considerations — https://www.algomox.com/resources/blog/stateful_vs_stateless_it_agents 3. [bytebytego.com] Stateless Architecture: The Key to Building Scalable and Resilient Systems — https://blog.bytebytego.com/p/stateless-architecture-the-key-to 4. [linkedin.com] Stateful vs Stateless Design — What’s the Difference? — https://www.linkedin.com/posts/nikkisiapno_stateful-vs-stateless-design-whats-the-activity-7337085407068680192-VIr3 5. [aerospike.com] Stateful vs. stateless architecture for scalable systems explained — https://aerospike.com/blog/stateful-vs-stateless-architecture-guide
관련 글 추천
- https://infobuza.com/2026/06/07/20260607-mbcqk9/
- https://infobuza.com/2026/06/07/20260607-qc1jtt/
FAQ
상태 유지(Stateful) 에이전트가 상태가 없는(Stateless) 에이전트보다 응답 속도가 느린 이유는 무엇인가요?
상태 유지 에이전트는 매 요청마다 사용자의 이전 히스토리와 맥락(컨텍스트)을 조회하고 처리해야 하기 때문에 개별 응답 속도가 더 느려집니다.
100만 명 규모의 서비스에서 서버 메모리에 세션을 저장하는 방식의 문제점은 무엇인가요?
사용자가 처음 접속한 서버로만 연결되어야 하는 '스티키 세션' 설정이 필요해 로드 밸런싱이 복잡해지며, 서버 장애 시 해당 서버에 저장된 수천 명의 데이터가 소실될 위험이 있습니다.
초대규모 환경에서 AI 에이전트의 확장성을 높이기 위한 아키텍처 패턴은 무엇인가요?
상태를 Redis와 같은 고속 외부 저장소로 분리하는 '상태의 외부화'와, CQRS 및 이벤트 기반 아키텍처(EDA)를 도입하여 상태 변경을 비동기적으로 처리하는 '비동기화' 전략이 필요합니다.
모든 상태를 클라이언트의 요청(Request)에 담아 보내는 방식의 단점은 무엇인가요?
요청 크기가 비대해지면서 네트워크 대역폭 소모가 심해지고, 결과적으로 전송량 증가가 성능 저하로 이어지는 역설적인 상황이 발생할 수 있습니다.
상태 유지 에이전트가 개별 응답 속도는 느리지만 사용자 경험 측면에서 갖는 장점은 무엇인가요?
사용자의 맥락을 기억하므로 사용자가 정보를 반복해서 입력할 필요가 없게 만들어, 결과적으로 전체적인 작업 완료 시간(Task Completion Time)을 줄여줍니다.